# Why Run Just One AI Tool When You Can Run Ten in Parallel?
Greetings from the research lab. I'm keeping this one intentionally light--just a quick flow of thoughts to lower the bar for hitting publish.
I've been playing around a lot with different AI models and AI tools in general - ranging from chat apps, CLI tools, background agents, text-to-speech, speech-to-text models, and so on. The field moves fast, and tools change quickly.
The MULTI-AI-CLI-TOOL-3000 Experiment
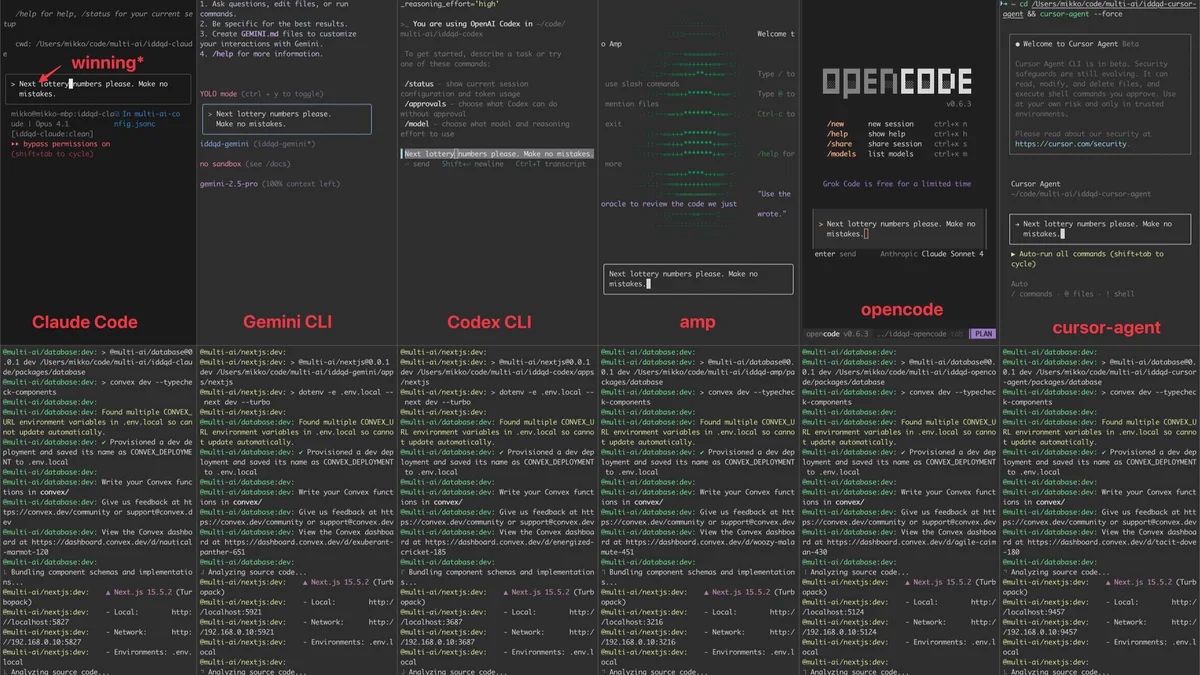
One of the most interesting experiments lately has been my MULTI-AI-CLI-TOOL-3000. With this tool, I can run multiple AI CLI tools in parallel. Here's the current workflow for most of my app/hack feature development:
- Isolated Environments: Every feature gets an isolated environment via Git worktrees
- One-Command Setup: The environment is initialized, and the DB, backend, and frontend are ready to go with one command - fully isolated
- Parallel Execution: I spawn multiple terminals with AI CLI tools running and feed the same prompt to all of them
- Performance Comparison: Once tasks start finishing, I compare which one did the best job and continue prompting with that one
- Integration: Once complete, I merge to main. Repeat.
Example Workflow
A short example of a prompt (usually these have a lot more detail):
"Add a settings panel to this SwiftUI macOS menubar app. In the settings panel, the user can select whether the app starts at login and whether it has a dock icon. Also, add an 'About' tab that shows an OIIA cat spinning. Update AGENTS.md, but keep it brief."
The implementation of this feature environment isn't the interesting part; it's the experience gained from the models and tools.
Current Performance Rankings
Until the last couple of weeks, Claude Code had easily been the best tool for getting things done. Opus 4.1 is a great model, and Sonnet 4 can also implement things. But then came GPT-5 and Codex CLI.
Currently, the success rate (via comparison) is:
- 50% Codex (GPT-5, high reasoning)
- 35% Claude Code (Opus-4.1)
- 14.9% Others
- 0.1% Gemini
Gemini models are nice and cheap, but with Gemini CLI, they've never produced anything good compared to the others. CLI tools are catching up to Claude Code overall, and Codex with GPT-5 has been excellent lately. A couple of months ago, Claude Code was almost always the best one.
What I'm Learning
This whole experiment has the effect that I'm learning not only how different models behave but also - just as importantly - how the CLI tools interact with them. Tool usage, reasoning, context handling, to-do lists, and knowledge management all affect how well tasks get completed.
I'm almost daily amazed at how well tasks are implemented and how complex tasks these things can complete. It still takes a lot of preparation and work, though. And just a reminder: these things don't give you the next winning lottery numbers.
Next Steps
I'll wrap this up here and continue with some more specific things later on. The rapid evolution in this space means these rankings could shift again in the coming weeks, but the parallel testing approach has proven invaluable for understanding the strengths and weaknesses of different AI tools.